Design Thinking + maskinlæring = sant
Hvordan to ikke-teknologer lærte å elske algoritmer på Stanford d. school.

Ofte hører vi kunder si: Vi har masse data, hva kan vi gjøre med dem? Det blir å starte i feil ende. Man bør heller tenke: Hva er det kundene våre trenger, og hvordan kan vi bruke data til å løse brukerbehov?
Gjennom NHHs Brytningstid-studium, besøkte vi nylig d. school på Stanford University, som er Design Thinking-metodikkens vugge. Der demonstrerte Carissa Carter, Director of Teaching and Learning, hvordan Design Thinking i samspill med maskinlæring kan brukes til å lage skalerbare, brukersentrerte løsninger.
Utforske problemområdet
Vi startet workshopen med en vanlig problemstilling: Hvordan ta imot nyansatte på en god måte? Vi listet opp utfordringene knyttet til onboarding og sorterte dem innenfor forskjellige kategorier: samfunn, system, opplevelser, produkt, teknologier og data. På denne måten kartla vi problemområdet, fikk oversikt over hvilke utfordringer den nyansatte møter og noen knagger å henge disse på.
Brukerprofil
Neste steg var å lage en brukerprofil, for å bevisstgjøre hvem vi lager løsninger for. Ved hjelp av en mal laget vi en bruker med diverse egenskaper og personlige preferanser. Videre forestilte vi oss hvilke opplevelser og følelser vår profil hadde i møte med utfordringen i å være ny på en arbeidsplass.

Konseptutvikling
Ved å se for oss elementene i en ideell brukeropplevelse for den nyansatte profilen vår, utarbeidet vi et grovt konsept, som vi trinnvis spesifiserte. Vi fastsatte konkrete tiltak som skal ivareta vår brukerprofil og hans behov, nemlig hvilken type mentor han skal få, hvilke kurs han trenger, hvilke behov han har sosialt og i forhold til kontorplass.
Ekspansjon gjennom maskinlæring
Denne historien kunne sluttet her, men nå kommer tvisten frem: Hvordan kan vi ekspandere løsningen slik at den får nytte for et stort antall mennesker med ulike behov? Ved hjelp av maskinlæring kan vi lage en løsning som er universell på den måten at den kan aggregeres opp, og passe mange ulike behov. Ved å gjenkjenne mønster i dataene, kan man forutse en rekke ulike brukerbehov og skreddersy onboarding-løsningen til ulike typer nyansatte.
Første skrittet på veien mot ekspansjon er å utforske hvilke typer data vi kan benytte for å utvide løsningen. Hvilke data kan hjelpe oss til å realisere konseptet, og hvor kan vi finne dem? Eksempler på datakilder for vårt konsept kan være Statistisk Sentrabyrå, sosiale medier og personalsystemer. Viktige fokus var: hvordan prioritere data, hvilke data mangler og hvordan unngå at dataene gjør oss forutinntatte. På den måten fikk vi et bevisst forhold til hvilke data som trengs for å realisere løsningen, hvordan få tak i dem og vurdere kvaliteten.
Vi elsker algoritmer
Ved hjelp av en kortstokk, «I <3 algorithms» fikk vi oversikt over hvilke statistiske metoder man kan benytte innen maskinlæring for å skalere løsningen. Slik fikk vi hjelp til å finne hvilke algoritmer som egnet seg for vårt konsept, og hvilke vi absolutt ikke burde benytte, for eksempel i forhold til personvern og etikk. I dette eksempelet landet vi på at vi ville teste ut algoritmen assosiasjon for å forutse nyansattes behov, og skalere løsninger basert på dette. Eksempel på assosiasjon satt på spissen: Hvis en nyansatt liker Mac, så liker hun sannsynligvis også iPhone, og vil sannsynligvis ha en mentor med like preferanser slik at vedkommende kan hjelpe for eksempel å koble til skriver fra Mac.

Vi ble veldig inspirert av workshopen, og ser frem til å ta metodikken i bruk, slik at vi kan hjelpe våre kunder til å benytte maskinnæring til å løse ekte brukerbehov. Det sies at data er den nye oljen, men det hjelper ikke hvis man ikke vet hvordan man kan skape verdi av det. Workshopen på Stanford viste oss at Design Thinking er en nyttig metodikk for å lykkes med maskinlæring.
Aktuelle kurs for deg som er interessert i å lære mer om maskinlæring og tjenestedesign:

Helsedirektoratet
Skal gi fastleger i Norge mer og bedre innsikt i egen praksis

Fiskeridirektoratet
Videreutviklet designet til Fiskeridirektoratet
RKBU Nord, UIT
NettOpp – en mobilapplikasjon for ungdom som har opplevd nettmobbing eller negative hendelser på nett.
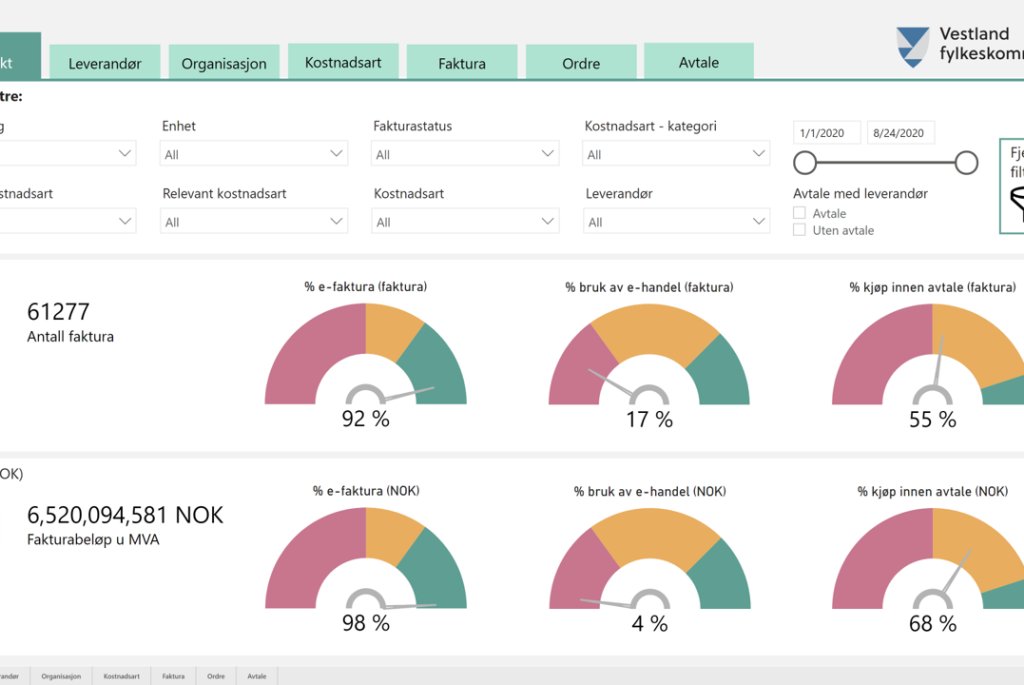
Vestland fylkeskommune
Utvikling av Power BI-rapport for innkjøpsseksjonen i Vestland fylkeskommune

Helsedirektoratet
Utforming av enklere og mer brukervennlig innsynsløsning i helseregisterdata for innbyggere

Etat for barn og familie