
Bergen kommune
Maskinlæringsmodell optimaliserer avløpssystemet i Bergen kommune
For å forhindre forurensning fra avløpssystemer er det svært viktig å oppdage blokkerte rør eller rør som har sprukket. Sammen med Bergen Vann har vi sett på hvordan vi kan finne slike feil raskere og mer effektivt. Løsningen ble en maskinlæringsmodell.
Utfordringen
I et avløpssystem tar pumpestasjonene imot vann fra kloakk og overvann. Mengden vann som pumpes gjennom disse gjenspeiler nivået i resten av avløpssystemet. Ideen bak dette prosjektet var at pumpestasjonene kan fungere som indikatorer for tilstanden til systemet, slik at jobben med å oppdage uregelmessigheter kan effektiviseres betraktelig.
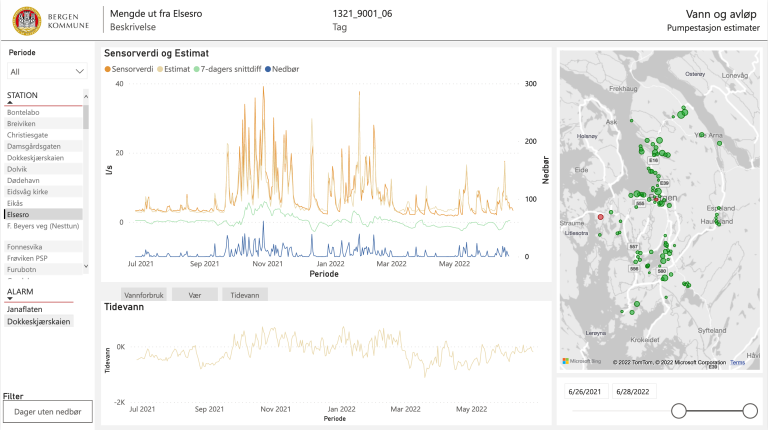
Vi fant ut at vi med ganske stor presisjon klarer å estimere hvor mye vann som skal gå gjennom pumpestasjonen, og om vi da ser at estimatet ikke stemmer overens med den målte verdien så indikerer det at det har skjedd noe med avløpssystem eller vannforsyning.
Løsningen
Hvor mye avløpsvann som går gjennom pumpestasjonene, avhenger av en rekke faktorer. I dette prosjektet valgte vi å beregne vannmengden ut fra faktorene vi anså som de viktigste. Relatert til kloakk fra husholdninger, industri og offentlige bygg har vi inkludert målt vannføring i vannledningsnettet, tidspunkt på dagen og ukedag. For overvann bruker vi meteorologiske målinger, nedbør, temperatur, og tidevannstabeller. All denne informasjonen sendes nå kontinuerlig til en maskinlæringsmodell.
Maskinlæringsmodellen er en deep learning modell og har blitt trent opp med historiske data fra tidligere år. I pumpestasjonene er det nemlig plassert sensorer som måler hvor mye vann som pumpes til enhver tid. Treningsalgoritmen fikk vite hvor mye vann som faktisk har gått gjennom pumpestasjonen hver eneste time gjennom hele året, og har lært seg hvordan informasjonen den får tilsendt skal brukes for å estimere riktig mengde.
Etter at treningen ble gjennomført kan nå målinger av de ovennevnte faktorene for de siste dagene mates inn til modellen, som gjør estimater for pumpemengder slik at vi kan sammenligne dette med faktiske mengder vann som pumpene har pumpet.
Hvis estimatene er gode, vil estimater og målte vannmengder i pumpestasjonene stemme overens. Hvis de ikke stemmer overens, indikerer dette at noe har skjedd med systemet som tilfører vann til pumpestasjonen. Vi har satt opp et alarmsystem som trigges hvis avvik over de siste syv dagene er større enn en terskelverdi som er relativ til de målte pumpemengdene.
Ved å få identifisert pumpestasjoner som avviker fra normalen kan driften fokusere på tilsyn med disse få i stedet for å sjekke alle de ca 200 pumpestasjonene. Dette gir en mer målrettet og effektiv drift.
Foreløpige resultater – hva har vi lært så langt?
Så langt har vi skaffet erfaring med hvilke faktorer som betyr noe for vannmengde i pumpestasjonene, og vi har lært hvordan vi best kan designe og trene deep learning-algoritmen. Alt fra trening, estimering og innhenting av data gjøres i Bergen Kommunes skyløsning, den såkalte datasjøen, og resultatene presenteres i en PowerBi-rapport.
Bergen har mange avløpspumpestasjoner som betjener mange ulike områder med vidt forskjellige tilsig av avløpsvann, og noen av pumpestasjonene fanges ikke godt nok opp av modellen så det er mulig at vi fremover trenger individuelle tilpasninger for disse pumpestasjonene. Vi vil videre også se på flere datakilder som for eksempel målinger av snødybde. Etter hvert som vi forfiner trening og estimering vil vi se videre på når det er grunn til å varsle om at noe kan ha skjedd med avløpssystemet.
Ansvarlig kontor: Bergen
Kontakt oss
