GTC 2021 – NVIDIAs årlige AI konferanse
Mine erfaringer og refleksjoner etter å ha deltatt på en meget interessant utgave av GTC.


I år deltok jeg på NVIDIAs virtuelle GPU Technology Conference (GTC). Dette er en av verdens største AI konferanser og skjer vanligvis på flere ulike tidspunkter i løpet av året, på ulike lokasjoner (Europa, Amerika, Sør-Amerika, etc.). Jeg tolker det slik at på grunn av at det er virtuelt i år, så er utvalget og kvaliteten på foredragsholdere enda større og sterkere enn vanlig, da personer som Turing vinnerne Yoshua Bengio, Geoffrey Hinton og Yann LeCun gjerne ikke deltar på den europeiske utgaven av GTC, men heller den amerikanske, mens personer som Jürgen Schmidhuber deltar på den europeiske, ikke den amerikanske.
GTC er et ukelangt arrangement fra 12.04.21 til 16.04.21., hvor de forventer over 100.000 deltagere, med 1.500 sesjoner (foredrag og trening) og flere enn 2.200 foredragsholdere. Dette akkumulerer til over 1.100 timer med informasjon fra 11 ulike industrier spredt over 13 ulike temaer. Inntrykket mitt er at alle foredrag er tatt opp og kan sees om igjen på GTC sine hjemmesider: gtc21.event.nvidia.com.
Intro
Det hele startet med en keynote fra NVIDIAs CEO Jensen Huang hvor han fortalte om alle fremskrittene NVIDIA har gjort det siste året og deres ikke-så-veldig beskjedne mål «Building tools for the Da Vinci’s of our time» med deres imponerende utvikling innenfor chiper, med søkelys på GPUene deres.
Det største fremskrittet var uten tvil «Omniverse» – en virtuell verden i skyen hvor miljøene følger den virkelige verdens fysiske lover. Her fokuserte de på muligheten for å lage digitale tvillinger av fabrikker, blant annet fabrikkene til BMW. Ved å lage en digital tvilling av deres fabrikker med muligheten for å representere mennesker, biler, verktøy eller lingnende kan de planlegge og se hvordan planene vil fungere i virkeligheten, og dermed optimalisere pipelines. I tillegg kan de forutse mulige problemer med diverse komponenter over tid.
Disse tingene i seg selv var utrolig kult, og det var fascinerende å se demoene som viser de ulike måtene å vise at elementene i den virtuelle verden følger de fysiske lovene. Men, kanskje det aller kuleste var muligheten for at du kan ta på deg en «motion suit» i den virkelig verden for å «jobbe» i den virtuelle verden – tenk «Ready Player One» 0.0.0.1. Dersom du ikke har en sånn drakt kan en også bruke digitale mennesker som er trent på bevegelsesdata fra deres egne ansatte.
Videre snakket Huang om oppdatert hardware i form av deres DGX-stasjoner for både datasentre i form av skyen og «personlige» PCer. Ved hjelp av deres GPU-fokuserte datasentre har de akselerert mulighetene for høy compute, som hovedsakelig er tiltenkt AI-utvikling. GPUer gir som nevnt økt fart for AI-utvikling, men de sliter med minne-størrelse, i forhold til CPUer. Videre har de akselerert farten på intern computing ved en såkalt DPU. Alt dette er gjort mulig med kombinering av tre ulike chiper: Grace (CPU) + DGX (GPU) + Bluefield (DPU).
Utenom dette var det fascinerende mange «Today we are announcing …» med nye fremskritt og produkter utviklet siste året:
- Bibliotek for Quantum Computing
- Pre-trente modeller for medisin discovery – både bilder og NLP
- AI-plattform – flere AI-biblioteker med muligheten for å preppe data, trene modeller, simulere, og få ut i produksjon
- TAO – et rammeverk som tillater flere entiteter å trene på samme modell uten å dele data. Dette er spesielt relevant for helsevesenet hvor ulike sykehus ikke ønsker å dele data med hverandre, men ønsker å bidra til å trene modeller på større mengder data enn mulig tidligere
- Jarvis – SOTA konversasjons AI som kan deployet alle mulige steder som i cloud, i edge i en butikk, på en NVIDIA PC, robot som kjører på en Jetson maskin, etc. Jeg legger dog inn en formell klage på bruken av navnet «Jarvis».
- Merlin – Anbefalingssystem hvor du kan kjøre ETL, trening og inference på anbefalingsmodeller
- Maxine – En feature NVIDIA har utviklet for virtuelle møter med funksjonalitet som blant annet øker kvaliteten på sendingen, og av en eller annen grunn kan «fake» øyekontakt med kamera. Altså, dersom du er i et virtuelt møte på Teams, og du ser vekk fra kamera, så vil denne funksjonaliteten fake at øynene dine fortsatt ser i kameraet – hvordan dette ble et tema er jeg veldig nysgjerrig på.
Salg
På denne konferansen er det utvilsomt mye søkelys på salg for NVIDIA – fra keynoten til Huang, til diverse paneldiskusjoner ledet av ledere fra NVIDIA hvor spørsmålene hovedsakelig gikk ut på «Hvordan bruker dere produkt X og hvordan har det revolusjonert deres bedrift?». Til tross for dette var det mulig å trekke ut noen interessante momenter en kan kjenne seg igjen i. Dette kom best frem under en diskusjon med temaet «NVIDIA Inception Insights and trends from around the world» hvor «Inception» er NVIDIAs avdeling for startups. Her snakket de om de ulike stadiene innenfor AI og at de følte mange bedrifter har drevet med «wave skipping» - altså at de hopper over nødvendige steg for å raskere få et produkt som kan brukes, og at dette koster i det lange løpet.
Videre var det en leder fra en startup i Marokko som har laget en løsning for å bekjempe illegal fisking med droner. Disse dronene er helt autonome (selvkjørende) og all prosessering og tolkning av input kjøres lokalt, in-flight, som krever relativt stor komputasjonskraft. Disse har faktisk en norsk investor og, så vi skal ikke se bort ifra at denne typen produkt kommer til Norge om noen år.
Forskning
Hovedfokuset mitt for denne konferansen var å få med meg de nyeste og kuleste fremskrittene innenfor feltet AI. Det er ingen tvil om at disse kommer best frem i presentasjonene av diverse forskere, og med årets line-up var det utrolig mye gøy å sette tennene i.
Årets presentasjoner, som jeg fikk med meg, sentrerte seg rundt noen hovedtemaer, oppsummert av Yann LeCun i sitt foredrag «The Energy-Based view of Self-Supervised Learning»:
«Det er tre utfordringer for AI og maskinlæring i dag:
1. Evnen til å lære med mindre datamengde/færre prøvinger – minimere kravene til mengde data/kjøringer dagens supervised learning og reinforcement learning har
2. Evnen å resonnere – forene fornuft og læring
3. Lære å planlegge komplekse handlingssekvenser – lære en hierarkisk representasjon av en salgs handlingsplan»
Altså, hvordan kan du gjøre maskinlæringsmodeller mer generaliserbare? Hvordan kan du oppnå SOTA-resultater uten den ekstremt store mengden data du vanligvis ser ved hjelp av «self-supervised learning»? Og hvordan kan du kombinere de viktigste fremskrittene innenfor AI til å lage et system med en hierarkisk struktur? I tillegg var det en presentasjon om historien til universet og hvordan utvikling innenfor PCer og (moderne) AI relaterer til dette, med en spenstig prediksjon om hva som skjer de neste årene.
Generaliserende AI
Målet om å lage maskinlæringsmodeller som generaliserer ble motivert av en spøk fra Roey Mechrez (CTO, Co-founder, BeyondMinds): «en giraff går inn i en bar for hunder og katter, og bartenderen sier ‘jeg er 99% sikker på at du er en hund’». Dette er gjerne ikke en «haha»-vits, men det belyser problemet med at dersom en modell får inn data den ikke er trent på, så vil dagens modeller gi feile resultater.
Dette er tett koblet til «garbage in – garbage out» problemstillingen innenfor AI, fordi det er vanskelig å nøyaktig definere distribusjonen av data en modell kommer til å treffe på. Det ble sagt at dette (nøyaktig definere en distribusjon) er intet mindre enn «the holy grail of AI».
En praktisk måte å jobbe mot dette problemet ble presentert på «Addressing the garbage-in, garbage-out problem in DL models» hvor Roey Mechrez foreslo flere ting, men fokuserte på å legge inn to relevante filtre i pipelinen:
1. Out of distribution detection (OOD) – et filter som legges før data sendes inn i modell. Her utføres en matematisk analyse av input som sier om input data er lik nok til eksisterende distribusjon av data (treningssettet). Dersom ja, send videre, dersom ikke, send videre til et menneske for videre prosessering.
2. Usikkerhetsfilter – et filter som legges inn etter input er tolket av modell. Denne ser på usikkerhetsscoren til modellen, og dersom usikkerhet > X%, så send videre til et menneske for videre prosessering.
En litt mer teoretisk og teknisk fremstilling av denne problemstillingen ble gitt av Yoshua Bengio i foredraget «Human-inspired inductive biases for casual reasoning and out-of-distribution generalization». Overskriften betyr, slik jeg har skjønt det, at speaker har tatt inspirasjon fra hvordan mennesker bruker tidligere erfaringer til å løse nye problemer eller gjøre antakelser i hverdagen når det oppstår situasjoner en ikke har sett før. Et eksempel: første gang du setter deg inn i en bil, og du kjører ved siden av et stort stup – da trenger du ikke erfaring med å kjøre utenfor et stup for å vite at det er dumt å gjøre. Du bruker erfaring fra andre situasjoner i livet til å generalisere for en hendelse som «ikke er i din distribusjon».
Dr. Bengio snakker om to forskjellige systemer beskrevet i boken «Thinking fast and slow» av Daniel Kahneman:
1. Rask – det intuitive systemet som baserer seg på instinkt og følelser og implisitt kunnskap, altså kunnskap du har tilegnet deg ved å se på eksempler uten egentlig helt å forstå
2. Sakte – det logiske systemet som baserer seg på erfaringer og eksplisitt kunnskap, og er sekvensiell, matematisk, etc.
Dagens AI-løsninger er veldig gode på system 1, det raske, men vi har ikke oppnådd system 2, det logiske. For å få dette til må vi legge til en form for «inductive bias», også kjent som learning bias som vi alle har lært at vi skal unngå i modeller, og begrensninger om hverandre, slik at modellen kan generalisere kunnskap. For eksempel, dersom den slipper et objekt (med en viss vekt) fra en elle annen høyde, så vil objektet falle ned på bakken. Dersom den lærer dette ved å bruke en ball først så skal denne leksjonen kunne relatere videre til en bamse, en stol, eller en penn. Denne kunnskapen skal også kunne brukes dersom det skjer en endring i oppsettet (kalt «casual intervention»), f.eks. den mister ballen, eller mister stolen.
Tanken her er at du endrer bare et par parametere i modellen ved slike endringer i miljø, men ikke hele modellen. Dette blir kalt «independent mechanisms» og kan knyttes til vanlig systemutvikling: ved en endring i ene delen av koden skal ikke det skape behov for endringer andre steder i koden.
Så, hvordan skal dette se ut i praksis – at bare spesifikke deler av en modell blir aktivert for spesifikke situasjoner? I 2015 ble NLP-verden revolusjonert av noe som heter «attention»-mekanismer som, slik jeg har skjønt det, gir muligheten for å vektlegge inputen i den forstand at «viktig» informasjon blir vektlagt høyere enn mindre viktig informasjon. Videre sier Dr. Bengio at denne mekanismen også kan velge hvilke nevroner i nettverket som skal aktiveres, og hvilke nevroner som skal samhandle med hverandre. Jeg tolker det dit hen at dette velges gjennom vektleggingen av input – i og med at nettverket essensielt bare reagerer på input. Dette relaterer til hvordan hjernen vår fungerer også, i den forstand at vi går sjeldent igjennom alle mulige alternativer, men hjernen «lager» noen gode kandidater til mulige svar, basert på input.
Self-supervised learning
En av de store utfordringene med dagens løsninger for «supervised learning» er tilgangen på merket (labeled) data, nødvendig for å trene modeller. Det krever mange timers arbeid, noen ganger av høyt utdannede profesjonelle, for å skape bare en brøkdel av datamengden nødvendig for at en modell skal oppnå tilfredsstillende resultater.
I dag virker det som om (en del av) løsningen på dette problemet er «self-supervised learning» (SSL). I motsetning til «supervised learning» så har du ikke merket data med SSL, og dette fører til langt mindre kostnader for å skape store treningsdatasett. LeCun hadde en definisjon på SSL (løst oversatt): «SSL fanger avhengigheter mellom avhengigheter, og gjør det mulig å predikere alt, basert på alt annet». Basert på dette kan du si at dette (løst) relaterer til out-of-distribution problemstillingen forklart tidligere.
Videre snakket LeCun om «Energy-Based Model Framework» (EBM) som er en arkitektur med mål om å forbedre SSL pipelinen. EBM er implisitte funksjoner som kan representere komplekse og «multimodale» (kombinering av ulike felt, som språk, bilder og tekst) avhengigheter mellom input (x og y).
EBM skiller seg fra vanlige feed-forward nettverk hvor du regner ut y basert på x, ved at EBM sammenligner x og y, og outputer et mål på hvor like/kompatible de er – denne verdien defineres som «energien». Så, dersom x og y er kompatible vil energien være lav, og dersom x og y ikke er kompatible vil energien være høy. Et eksempel på hva x og y kan være (for dette lurte jeg lenge på) er en rekke med bilder ordnet i stigende tidsrekkefølge, også kalt video, på 20 sekunder. Da kan x være de første 15 sekundene av videoen, mens y er de siste 5 sekundene. Modellen ser da på x og prøver å predikere y. EBM vil da regne ut hvor kompatible x og y er, og basert på dette oppdatere nettverket ved hjelp av energi-verdien. Dette blir kalt for «conditional EBMs» F(x, y) - Vi har alltid en observert x-variabel, og skal predikere y-variabelen.
Videre er det også «unconditional EBMs» F(y) – Vi har ingen x, bare y, så modellen prøver å fange opp de indre avhengighetene i de ulike komponentene i y. Et eksempel på dette er k-means.
I dag har SSL revolusjonert Natural Language Processing (NLP), og er på vei inn i bildedomenet også. Dette er spesielt relevant for sykehus o.l. - gjerne i en kombinasjon med transfer learning. Her har en gjerne mye data, men ikke mye som er merket og kostnadene for å merke dem er veldig høye. Ene eksperimentet beskrevet av LeCun var at de pre-trente en språkmodell på 960 timer med umerket tale, for så å trene på 10 minutter med merket data. Her oppnådde de SOTA resultater som tidligere var satt med modell trent på 100 timer med merket data.
Det var utrolig mye spennende i dette foredraget, og vil anbefale den på det varmeste (gtc21.event.nvidia.com/media/The%20Energy-Based%20view%20of%20Self-Supervised%20Learning%20%5BS33268%5D/1_809kjdxq).
«(Part-whole)» hierarkier
Dr. Hinton forklarte sine tanker om et imaginært system med evnen til å se (vision system) kalt GLOM som er nærmere menneskelig oppfatning enn nåværende dype nett. Dette skal gjøres ved å kombinere tre store fremskritt innenfor AI:
1. Transformers – for å modellere språk
2. SSL – for å lære visuelle representasjoner
3. Generative modeller (av bilder) som bruker nevrale felt
Det som er litt interessant er at Hinton ønsker å bruke «contrastive learning» for SSL, som LeCun nevnte i sitt foredrag at var dyrere og oppnådde dårligere resultater enn «non-contrastive learning» - hva som er fasit gjenstår gjerne å se. Dog ble «contrastive learning» introdusert i 1992 av nettopp Hinton, så kanskje vi har svaret på spørsmålet der..
For de som er interessert: den store forskjellen mellom contrastive learning og non-contrastive learning kan forklares relativt enkelt. Vi husker at jeg beskrev contrastive-learning som at vi sammenligner datapunkter og ser hvor kompatible disse er, og basert på dette får vi en «energi»-verdi. Denne verdien brukes til å «pushe» energien til datapunktene – så «gode» datapunkter får lavere energi, mens «dårligere» datapunkter får økt energi. Vel, i non-contrastive learning så optimaliserer dette ved å sette en begrensning på antall datapunkter som kan ha lav energi. Dermed automatiserer du bort dette med å dytte opp de dårlige datapunktene – dette skjer av seg selv ved at «det er ikke plass» når gode datapunkter blir dyttet ned.
Uansett, for å representere et såkalt «part-whole» hierarki, foreslår Hinton å lage en embeddingvektor (en tabell med tall) for å representere et objekt, og duplisere denne vektoren ved flere lokasjoner i et bilde. Denne embeddingvektoren vil fungere som en pointer, og lar hver lokasjon i bildet vite hvilke objekter den har med å gjøre. GLOM er tiltenkt å ta inspirasjon fra biologien hvor hver celle i kroppen har ett komplett sett med instruksjoner for å lage proteiner, og det er miljøet til cellen som avgjør hvilke proteiner som faktisk kommer til uttrykk.
Måten dette systemet skal trenes på er ved å gi inn et bilde med manglende regioner, for så å predikere bildet i sin helhet – altså fylle inn de manglende regionene. Dette er slik vi har beskrevet SSL før, og er også sånn BERT (NLP) blir trent på tekst. Men, dette er ikke nok, så vi må legge til nevnte contrastive learning.
«Universets historie sett med AI-briller»
Den eksentriske professoren Jürgen Schmidhuber fra München er en karakter som ikke er altfor kjent i AI-miljøet og har kanskje ikke fått æren han fortjener – og dette er han ikke akkurat beskjeden om heller. Dette er gjerne grunnen til at foredraget «Modern Artificial Intelligence 1980s-2021 and Beyond» inneholder mer enn nok informasjon om hva han og hans Ph.d. studenter har oppnådd
innenfor AI og hvordan «amerikanerne» (alle som jobber i USA for Facebook, Google, etc.) har mer eller mindre bare kopiert ting de gjorde for 20/30 år siden.
Videre er professoren veldig glad i historien om at Dr. Hinton sa for lenge siden at «Nobody in their right mind would ever suggest to use plain gradient descent through backpropagation to train deep feedforward FNNs» - som naturligvis viste seg å være feil. Et kjapt Google søk om akkurat dette ledet meg inn i mange bloggposter og artikler om feiden mellom Schmidhuber og Hinton, så om noen kjeder seg og er ute etter litt «akademisk»-drama var det definitivt litt å ta i der.
Men, det presentasjonen faktisk handlet om var veldig spennende – Schmidhuber starter med å si at han tror at menneskeheten kommer til å «evolve» rundt år 2040. Dette er basert på kalkulasjoner han har gjort som sier at det er en eksponentiell akselerasjon av store fremskritt sett fra det menneskelige perspektiv. Om en starter med The Big Bang, for så å ta tidsintervall på ¼ siden, og fortsetter videre så vil et mønster formere seg. «In fact, history seems to converge in a Omega-point in the year 2040 (or so).» Så begynner matten:
Omega - (13.8 milliarder år (Big Bang) / 4) ~ 3.5 milliarder år à Liv startet på denne planeten
Omega - (3.5 milliarder år / 4) ~ 0.9 milliarder år siden à Første dyrelignende liv i havene
Omega - (900 millioner år / 4) ~ 220 millioner år siden à Første pattedyr
Omega - (220 millioner år / 4) ~ 54 millioner år siden à Første primater
Omega - (54 millioner år / 4) ~ 13 millioner år siden à Første hominiden
Omega - (13 millioner år / 4) ~ 3.5 millioner år siden à Starten på teknologi – første steinredskaper
Omega - (3.5 millioner år / 4) ~ 800.000 år siden à Neste teknologiske utviklingen – kontrollert flamme
Omega - (800.000 år / 4) ~ 200.000 år siden à Anatomisk moderne menneske
Omega - (200.00 år / 4) ~ 50.000 år siden à «Atferdsmessig» moderne menneske
Omega - (50.000 år / 4) ~ 13.000 år siden à Sivilisasjon – husdyr, jordbruk, Amerika oppdaget
Omega - (13.000 år / 4) ~ 3.300 år siden à Jernalderen - første populasjonseksplosjon
Omega - (3.300 år / 4) ~ 800 år siden à År 1200 – Våpenutvikling med krutt, kanoner, raketter, osv.
Omega - (800 år / 4) ~ 200 år siden à Midten av 1700 tallet – Industrielle revolusjon, moderne medisin, populasjonseksplosjon, osv.
Omega - (200 år / 4) ~ 50 år siden à År 1990 – informasjonsrevolusjon, mobiler, PCer, internett, moderne AI, kalde krigen slutt
Omega - (50 år / 4) ~ 9 år frem i tid à 2030 – «da vil utrolige ting skje»
Jeg er litt usikker på jeg skal ringe Konspirasjonspodden eller legge opp aksjekjøp i forhold til dette. Uansett så er det litt gøy med slike mønstre.
Fun fact: Den første autonome bilen ble først testet ut på 1980-tallet i München, og i 1994 kjørte en bil på motorveien i opptil 180 km/t, uten GPS og kjørte forbi andre biler.
Videre forteller Schmidhuber om de største fremskrittene innenfor moderne AI:
- Første datamaskinen ble laget som gjennomførte 1 «elementær operasjon» (1941)
- Første deep learning nettverk trent i Ukraina (Sovjetunionen, 1965)
- Moderne backpropagation (Finland, 1970)
- RNNs (80-tallet)
- Teorien som ga opphav til et av forrige tiårets store oppfinnelser: GANs (90-tallet)
- LSTMs (1997)
- Første paperen som nevnte «learn deep» hvor begrepet «deep learning» kommer fra (2005)
- DanNet – første konvolusjonelle nettverk som vant alle bildegjenkjenningskonkurranser (2011).
o Fun fact 1: AlexNet som kanskje er mest kjent bygger på DanNet.
o Fun fact 2: Konvolusjonelle nettverk er visstnok en teori fra Japan tilbake på 1970-tallet.
- Policy Gradients for LSTMs (2012) – Reinforcement learning modell som har vunnet over profesjonelle Dota og StarCraft spillere
NOTE: Det viser seg visstnok at RNNs er de mest kraftfulle nevrale nettverkene som finnes, fordi de er essensielt «generelle computere». Beviset ligger i at et par nevroner kan implementere en NAND gate. Og et nett av NAND gates kan emulere en CPU.
Oppsummering
Årets GTC har vært utrolig spennende og lærerik, og det er skikkelig kult å se hvordan «de store» presenterer ting, hvordan de også har ting de ikke vet hvordan fungerer og har spørsmål om, og at de også er menneskelig i den forstand at smålige ting som sjalusi og mangel på annerkjennelse tar så stor plass.
Det er ingen tvil om hva som er fokusområdet innenfor AI akkurat nå i form av generalisering og effektivisering, og det virker ikke som om noen har noen endelige svar på dette (enda), men som tidligere ser jeg for meg at neste år vil det være noe nytt igjen som tar alles oppmerksomhet. Uansett hva det er så gleder jeg meg til å lære om det ved å søke etter annethvert ord som blir sagt i slike foredrag.

Utdanningsdirektoratet
Løfter læreplanen til skyen

Nordland fylkeskommune (Nfk)
Forprosjekt for ny billettsalgsløsning og ny kundeapp for billettkjøp på buss for Nordland fylkeskommune

Viken fylkeskommune
Dybdeintervjuer ga verdifull innsikt om Viken fylkeskommune
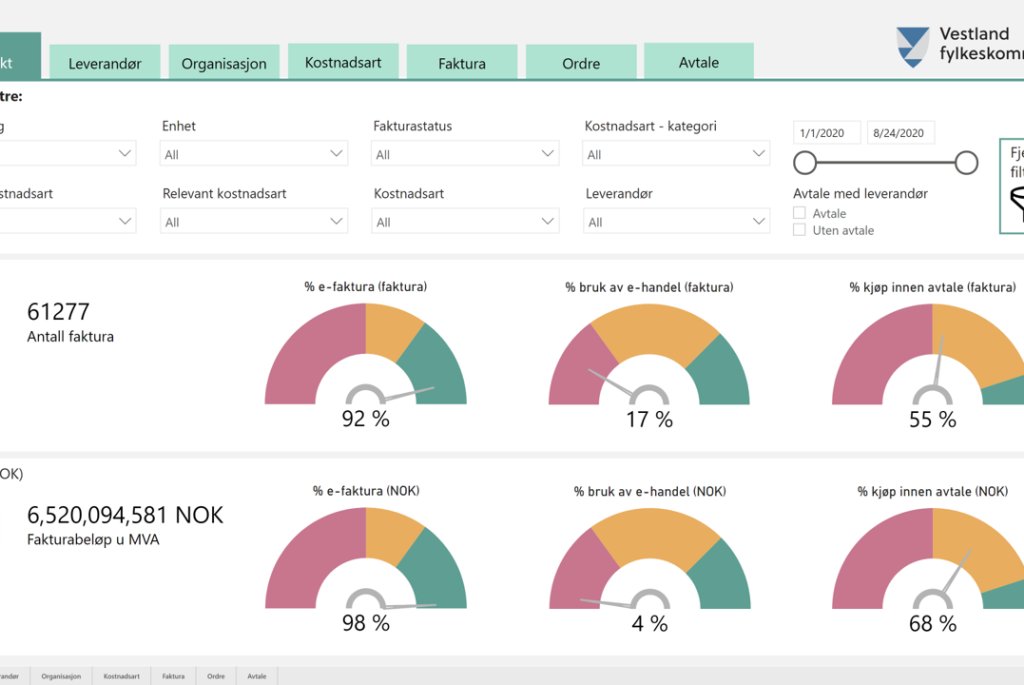
Vestland fylkeskommune
Utvikling av Power BI-rapport for innkjøpsseksjonen i Vestland fylkeskommune

Helsedirektoratet
Utforming av enklere og mer brukervennlig innsynsløsning i helseregisterdata for innbyggere
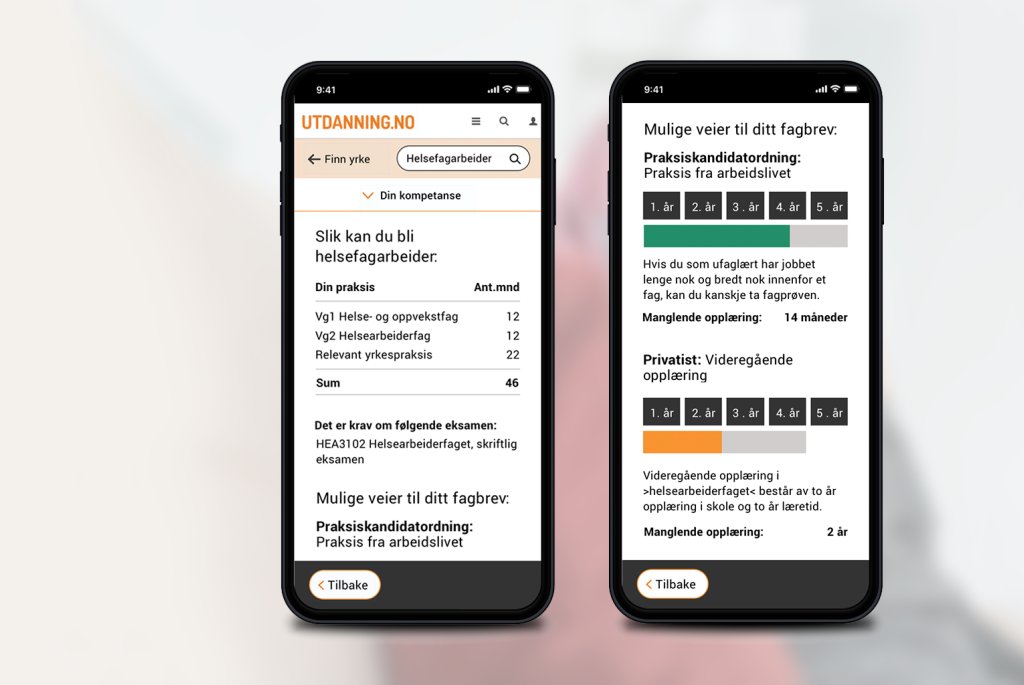
Kompetanse Norge