I denne bloggposten vil vi dele litt om hvordan teknologien fungerer, dens praktiske anvendelser, og hvilke muligheter den åpner for i fremtiden.

Tsetlin-maskiner er en norskutviklet AI-teknologi som kombinerer forklarbarhet med energieffektivitet. Som et friskt alternativ til tradisjonelle «svarte boks»-løsninger, har Tsetlin-maskiner vist sitt potensial på flere områder. Vi har begge jobbet med Tsetlin-maskiner på ulike måter og synes de er utrolig spennende, spesielt fordi de gir et alternativ til nevrale nettverk.
Hvorfor Tsetlin-maskiner?
Forestill deg en kunstig intelligens som forener rask læringsevne med en mer åpen og transparent beslutningsprosess. Dette er prinsippet bak Tsetlin-maskinen (TM), en norskutviklet teknologi innen AI. Dette er ikke en språkmodell og heller ikke et nevralt nettverk, men en egen variant innen AI.
Forklarbarhet
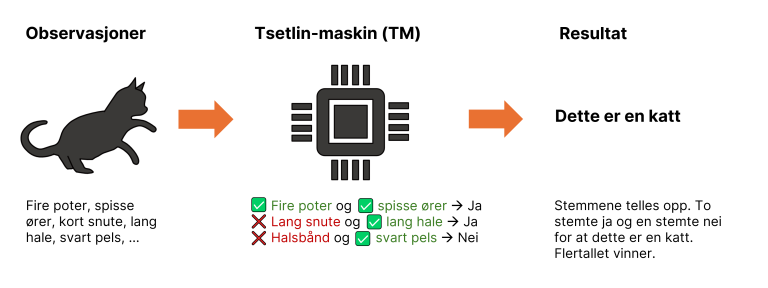
Kjernen i Tsetlin-maskinen er dens oppbygning av små byggesteiner kalt «Tsetlin automata». Hver automata opererer med to tilstander – «ja» og «nei» – og når mange av disse samarbeider, kan de gjenkjenne mønstre og løse komplekse oppgaver, for eksempel innen bildeklassifisering.
En vesentlig fordel med TM er at en ferdigtrent modell kan representeres som en sammensetning av enkle logiske porter (som AND og OR), slik illustrert i figuren under. Det betyr altså at hvert valg den tar kan spores tilbake til et enkelt ja/nei-valg. Dette er viktig når man trenger å forklare nøyaktig hvorfor teknologien tar de beslutningene den gjør. Dette gir en løsning der beslutningsgrunnlaget er lettere å etterprøve enn i nevrale nettverk.
Energieffektivitet
Så hva skiller denne teknologien fra andre? For det første bruker den lite energi og lærer raskt, noe som er bra for små dingser som ikke har så mye strøm til rådighet, som for eksempel smarthjem-løsninger eller industrielle sensorer. Forskere sier at denne metoden kan bruke hele 10.000 ganger mindre energi enn dagens smarte chiper, og være 1.000 ganger raskere (Kilde: Kan norsk oppfinnelse revolusjonere kunstig intelligens?). I praksis betyr det at teknologien raskt lærer seg å gjøre det den skal.
Åpenhet
Teknologien er åpent tilgjengelig, og alle har mulighet til å teste den for egne formål. Forskere som arbeider med Tsetlin-maskiner legger stor vekt på åpenhet og tilgjengelighet, og deler ofte resultater tidlig for å gjøre dem umiddelbart nyttige for offentligheten. De publiserer gjerne upublisert materiale på arXiv, og gjør også kildekode fritt tilgjengelig for andre å bruke og videreutvikle.
Hva skiller Tsetlin-maskiner fra andre metoder?
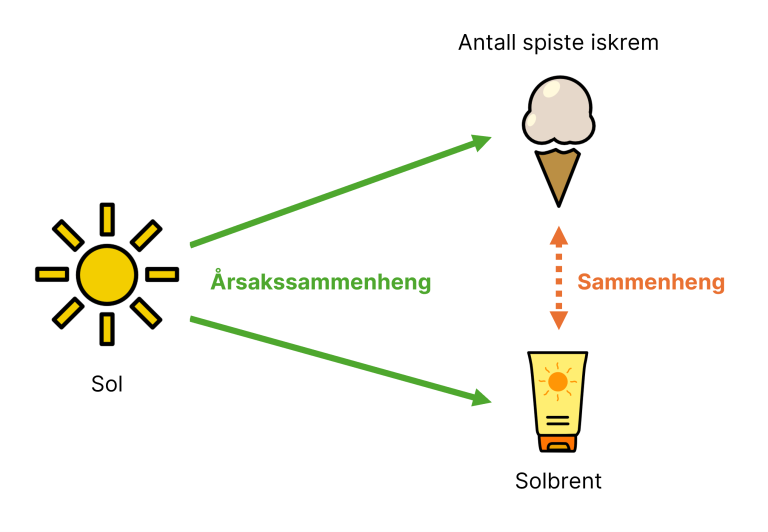
I motsetning til nevrale nettverk, som primært er gode til å finne mønstre basert på korrelasjoner i data, fokuserer Tsetlin-maskiner på å identifisere årsakssammenhenger (og ikke bare sammenhenger). Nevrale nettverk har en tendens til å oppdage korrelasjoner, som for eksempel at flere tilfeller av solbrenthet henger sammen med økt iskremspising, og kan dermed trekke konklusjonen at iskremspising fører til solbrenthet.
Tsetlin-maskiner derimot, har som mål å finne den underliggende årsaken, som i dette eksempelet ikke er at iskremspising forårsaker solbrenthet, men at solen gjør det. Folk spiser mer iskrem når det er sol, og blir også oftere solbrent, noe som skaper en sammenheng, men ikke en årsakssammenheng. Tsetlin-maskinens styrke ligger i evnen til å skille mellom slike overfladiske sammenhenger og de faktiske kausale forholdene vi ønsker å forstå og handle ut fra.
Men hva skiller egentlig Tsetlin-maskiner fra beslutningstrær? Beslutningstrær benytter en grådig (greedy) tilnærming, der hver avgjørelse tas basert på lokal optimalisering uten å se det større bildet. Dette gjør at de ofte ender opp med suboptimale løsninger. Tsetlin-maskiner, derimot, har ikke denne begrensningen og kan derfor identifisere mer komplekse og dyptgående mønstre i dataene. I tillegg er beslutningstrær lite egnet for oppgaver som bildegjenkjenning, hvor Tsetlin-maskiner har vist seg å være mer effektive. Selv om det finnes noen overlappende konsepter mellom beslutningstrær og Tsetlin-maskiner, skiller de seg veldig fra hverandre i både metode og anvendelsesområde.
Hvilke problemer kan Tsetlin-maskiner løse?
Her er seks eksempler som illustrerer hva Tsetlin-maskiner kan brukes til:
Eksempel 1: Deteksjon av GPS-forstyrrelser
Nkom tester nå Tsetlin-maskiner for å skille mellom bevisste GPS-forstyrrelser og forstyrrelser som skyldes andre typer feil. Teknologien analyserer innkommende signaldata for å vurdere forstyrrelser og bestemmer hvilken kategori de tilhører. Denne evnen til å tolke komplekse mønstre gir en verdifull fordel i sikkerhetssensitive anvendelser hvor presis deteksjon, lavt strømforbruk og forklarbarhet er avgjørende. Tester viser at Tsetlin-maskiner klarer dette mer nøyaktig enn sammenlignbare nevrale nettverk i de testene som ble gjennomført.
Kilde: Nkom tester norsk KI-modell i jakten på GPS-forstyrrelser - Nkom og Interpretable Rule-based Architecture for GNSS Jamming Signal Classification | IEEE Journals & Magazine | IEEE Xplore
Eksempel 2: Forståelige regler for medisinsk tekstklassifisering
Tsetlin-maskiner har blitt testet for å analysere og klassifisere medisinske tekster, slik som journalnotater. Den lærer da forklarbare regler som «hvis 'utslett' OG 'reaksjon' OG 'penicillin', så betyr det 'allergi'». Resultatene viser at Tsetlin-maskinen i gjennomsnitt presterer på nivå med eller bedre enn tradisjonelle metoder som SVM og nevrale nettverk på slike oppgaver, og at den gir forståelige regler som forklarer avgjørelsene. Denne evnen til å finne forståelige regler viser at Tsetlin-maskiner kan brukes til klassifisering av medisinske dokumenter, og viser også metodenes potensiale for klassifisering av andre dokumenter.
Eksempel 3: Oppdage hjertearytmier (uregelmessige hjerteslag) med meningsfulle forklaringer
En type Tsetlin-maskin har også blitt testet for deteksjon av premature ventrikulære kontraksjoner (PVC), altså uregelmessige hjerteslag, i EKG-data. Tsetlin-maskinen lærer regler som beskriver spesifikke EKG-mønstre knyttet til arytmier. Resultatet viser at verktøyet oppnår sammenlignbar nøyaktighet som dype nevrale nettverk (CNNs), men med en transparent og tolkbar beslutningsprosess. Dette gjør det mulig å forstå nøyaktig hvilke EKG-mønstre Tsetlin-maskinen har brukt for å komme frem til sin konklusjon, og disse mønstrene samsvarer med medisinsk kunnskap, ifølge forskerne. Innen medisin er forklarbarhet viktig, spesielt for at leger skal kunne stole på automatiske verktøy i hjerteovervåkning i fremtiden, og dermed representerer dette kanskje et steg i riktig retning?
Kilde: [2301.10181] Interpretable Tsetlin Machine-based Premature Ventricular Contraction Identification
Eksempel 4: RSSI-basert lokalisering
I masteroppgaven «An Environment-Adaptive Approach to Indoor Localization» vises det at Tsetlin-maskiner kan forbedre nøyaktigheten i innendørs trådløse nettverk for lokalisering av objekter. Ved hjelp av en Regression Tsetlin Machine (RTM) – der én instans er tilknyttet hvert aksesspunkt – predikeres avstanden mellom en trådløs enhet og et aksesspunkt basert på signalstyrkene fra noden og alle aksesspunktene. Denne metoden utnytter komplekse sammenhenger i data med mye støy, og har vist seg å oppnå bedre presisjon enn tradisjonelle matematiske metoder.
Kilde: https://uia.brage.unit.no/uia-xmlui/handle/11250/2823874
Eksempel 5: Bruk til klassifisering av lovtekster
Tsetlin-maskiner har også blitt testet på å analysere tekststykker (såkalte «chunks») fra kontrakter for å avgjøre om en bestemt juridisk klausul finnes i teksten. Den lærer regler i form av logiske proposisjoner, for eksempel: «‘term of’ OG ‘this agreement’ OG ‘unless terminated’». Dette blir en forklarbar beslutningsregel for kategorien «Expiration Date». Hver klausul TM lærer fungerer som et stemmegivende element, og avgjørelsen tas basert på flertallsavgjørelse mellom positive og negative stemmer. TM gir høy presisjon og nøyaktighet i nesten alle kategorier, ofte bedre enn CNN-BiLSTM og FastText. Selv om BERT og RoBERTa har bedre nøyaktighet (med noen prosentpoeng), har TM en stor fordel med forklarbarheten. Hver beslutning kan spores tilbake til spesifikke tekstuttrykk (literals) som TM har lært. Dette er spesielt viktig i juss, hvor man må kunne begrunne AI-avgjørelser.
Kilde: Interpretable Text Classification in Legal Contract Documents using Tsetlin Machines
Eksempel 6: Bildeklassifisering
Tsetlin-maskiner er gode på bildeklassifisering, altså å si noe om hva et bilde inneholder, og klarer blant annet å oppnå sammenlignbare resultater som nevrale nettverk på benchmark-datasettet MNIST (Kilde: [1905.09688] The Convolutional Tsetlin Machine). I senere tid har forskere også klart å øke nøyaktigheten til Tsetlin-maskiner på CIFAR-10 datasettet, som inneholder fargebilder og enda flere kategorier
Hva er fremtiden for Tsetlin-maskiner?
Tsetlin-maskiner representerer en ny og spennende retning innen kunstig intelligens, med lavt energiforbruk, rask læring og forklarbare beslutningsprosesser. Ved å bruke enkle logiske regler i stedet for komplekse beregninger, gjør de det mulig å forstå hva modellen faktisk har lært – noe som er avgjørende i mange anvendelser.
Oppfinneren av Tsetlin-maskiner, Ole-Christoffer Granmo, sier i et intervju med forskning.no: «Tusenvis av forskere har jobbet med å gjøre dagens kunstige intelligens bedre. Vi må ta igjen 20–30 år med forskning» (Kan norsk oppfinnelse revolusjonere kunstig intelligens?). Altså, selv om det kan være fristende å sammenlikne dagens alternativer med ny teknologi, slik som Tsetlin-maskiner, er det kanskje en litt urettferdig sammenlikning?!
Dagens KI-teknologi krever store mengder energi, og for å redusere dette fotavtrykket trenger vi nye metoder. Tsetlin-maskiner et lovende fremskritt i denne retningen. Vi heier på norsk teknologi, og tror at denne teknologien kan ha potensiale til å bli nyttiggjort på enda flere områder fremover!
Vi håper du har blitt litt klokere og litt mer nysgjerrig på denne teknologien. Under finner du en praktisk demo - kanskje du liker å teste selv?
For deg som er ekstra interessert - En praktisk demo
For de som er interesserte, tenkte vi å vise hvordan du raskt kommer i gang med å ta i bruk Tsetlin-maskiner. Det beste stedet å begynne er kodebasen Tsetlin Machine Unified (TMU) tilgjengelig på GitHub. Denne kodebasen samler ulike implementasjoner av Tsetlin-maskiner på en plass og gjør det enkelt å ta i bruk. I dette biblioteket finner du installasjons-instrukser og enkle kodeeksempler.
For å kunne installere TMU-prosjektet på din egen maskin må du ha Python installert (fra www.python.org). Dersom du bruker Windows må du også ha installert MSVC build tools for å kunne bygge C-modulene til Tsetlin-maskinen. Du kan laste ned installasjonsprogrammet til MSVC build tools fra denne lenken: Microsoft C++ Build Tools - Visual Studio. I installasjonsprogrammet må du velge og installere pakken “Desktop development with C++”. Merk at denne pakken tar 6-7GB diskplass.
Etter dette kan du installere TMU-prosjektet med følgende kommando:
pip install git+https://github.com/cair/tmu.git
Merk at du kan kjøre Tsetlin-maskinen på CPU (slik vi gjør her) eller på et dedikert grafikkort. For å kunne kjøre på GPU må du ha et Nvidia-grafikkort med CUDA Toolkit og pycuda-pakken installert. Dersom du ikke ønsker å installere TMU lokalt, kan du også åpne en notisbok i Google Colab og installere TMU-biblioteket der. Da trenger du ikke å installere MSVC build tools eller CUDA.
Dersom du har gjort alt riktig så langt er du nå klar til å ta i bruk Tsetlin-maskiner! Så la oss se på et enkelt eksempel hvor vi bruker Tsetlin-maskinen til å klassifisere bilder fra det velkjente MNIST-datasettet.
Steg for steg: Bildeklassifisering med Tsetlin-maskiner

MNIST er et datasett bestående av 70 000 bilder av håndskrevne tall fra 0 til 9. Du kan lese mer om det på Wikipedia: MNIST database - Wikipedia. Dersom du har installert TMU har du også MNIST datasettet tilgjengelig. La oss nå hoppe videre til implementeringen.
Steg 1: Importer nødvendige moduler
Vi starter med å importere komponentene vi trenger fra TMU-prosjektet. Her importerer vi MNIST-datasettet og en Tsetlin-maskin bygget for klassifisering:
from tmu.data import MNIST
from tmu.models.classification.vanilla_classifier import TMClassifier
import numpy as np
Steg 2: Last inn og gjør klar datasettet
data = MNIST.load()
Datasettet er delt inn i 60 000 samples og 10 000 test samples. I input-dataen (x) er hver rad en vektor med 784 verdier. De 784 verdiene representerer pikslene i et 28 x 28 piksel bilde, hvor 0 representerer en mørk piksel og 1 representerer en hvit piksel. For å bruke konvolusjons-egenskapene til TMClassifier, omformer vi hver vektor til et array på 28 x 28 piksler. Tsetlin-maskinen vår vil deretter tolke input-dataen vår som bilder.
data[“x_train”] = data[“x_train”].reshape(-1, 28, 28)
data[“x_test”] = data[“x_test”].reshape(-1, 28, 28)
Steg 3: Lag en instanse av Tsetlin-maskinen
tm = TMClassifier(
number_of_clauses=200,
T=10_000,
s=5,
patch_dim=(10, 10),
max_included_literals=32,
weighted_clauses=True,
platform=”CPU” # eller “GPU”
)
Merk at når vi definerer en Tsetlin-maskin, må vi spesifisere ulike hyperparametere; presisjon (s), målverdi (T) og antall clauses. Antall clauses bestemmer størrelsen på modellen, hvor hver clause består av mange tsetlin-automataer. Dess flere “clauses” modellen har dess smartere kan den potensielt bli, men det vil samtidig ta lenger tid å trene den. Presisjon (s) og målverdi (T) påvirker hvordan modellen trenes. Det finnes ikke en universell formel på hvordan disse verdiene bør settes, så her må man nesten eksperimentere litt selv eller ta utgangspunkt i eksemplene som er tilgjengelige i TMU-prosjektet.
Vi spesifiserer også en parameter kalt patch_dim, som bestemmer hvor store område av bilde som blir delt opp og sendt inn i modellen. I dette eksemplet definerer vi at hver “patch” er 10 ganger 10 piksler.
Parameteren max_included_literals bestemmer hvor mange input-parametere (også kalt “features”) hver clause kan ta utgangspunkt i for å lære ulike mønstre.
Vi setter også weighted_clauses til å være “sann”. Dette gjør at hver “clause” i modellen kan ha ulik avveining i resultatet. Dette har vist seg å gjøre at man kan oppnå gode resultater med mindre modeller. Kilde: https://arxiv.org/abs/1911.12607v4
Steg 4: Tren modellen
for epoch in range(10):
print(“Epoch”, epoch + 1)
tm.fit(data[“x_train”], data[“y_train”])
Steg 5: Evaluer modellen
Deretter kan vi evaluere modellen. For å redusere tiden dette tar, velger vi 1000 tilfeldige rader fra trening- og test-dataen. Nøyaktigheten på test-dataen gir et mer realistisk anslag for hvordan modellen vil håndtere bilder den aldri har sett før:
train_indices = np.random.choice(len(data[“x_train”]), 1000, replace=False)
train_accuracy = (tm.predict(data[“x_train”][train_indices]) == data[“y_train”][train_indices]).mean()
print(f”Train accuracy: {train_accuracy:.4f}”)
test_indices = np.random.choice(len(data[“x_test”]), 1000, replace=False)
test_accuracy = (tm.predict(data[“x_test”][test_indices]) == data[“y_test”][test_indices]).mean()
print(f”Test accuracy: {test_accuracy:.4f}”)
Tips: For å følge med på fremgangen mens modellen trener, kan vi evaluere modellen inne i løkken vår i hver iterasjon.
Full kode
from tmu.data import MNIST
from tmu.models.classification.vanilla_classifier import TMClassifier
data = MNIST.load()
data[“x_train”] = data[“x_train”].reshape(-1, 28, 28)
data[“x_test”] = data[“x_test”].reshape(-1, 28, 28)
tm = TMClassifier(
number_of_clauses=8_000,
T=10_000,
s=5,
patch_dim=(10, 10),
max_included_literals=32,
weighted_clauses=True,
platform=”CPU”,
)
for epoch in range(10):
print(“Epoch”, epoch + 1)
tm.fit(data[“x_train”], data[“y_train”])
train_indices = np.random.choice(len(data[“x_train”]), 1000, replace=False)
train_accuracy = (tm.predict(data[“x_train”][train_indices]) == data[“y_train”][train_indices]).mean()
print(f”Train accuracy: {train_accuracy:.4f}”)
test_indices = np.random.choice(len(data[“x_test”]), 1000, replace=False)
test_accuracy = (tm.predict(data[“x_test”][test_indices]) == data[“y_test”][test_indices]).mean()
print(f”Test accuracy: {test_accuracy:.4f}”)
Resultat
Dersom du kjører denne kodesnutten og venter en stund vil du kunne se liknende resultater i terminalvinduet ditt:
Epoch 1
Train accuracy: 0.9646
Test accuracy: 0.9674
...
Epoch 10
Train accuracy: 0.9832
Test accuracy: 0.9812
Vi oppnår ca. 98% nøyaktighet på test-dataen. Ikke verst! Men ved å justere parameterne nevnt ovenfor, og antall treningsepoker vil du kunne oppnå andre resultater.
Vil du grave enda dypere?
Den originale implementasjonen av Tsetlin-maskinen finner du her: https://github.com/cair/TsetlinMachine. Hvis du ønsker enda mer detaljer om Tsetlin-maskiner, har oppfinneren skrevet en bok om dem, som du finner på denne lenken: Home - An Introduction to Tsetlin Machines. Kode-eksemplet ovenfor er basert på et eksempel hentet fra TMU-biblioteket. Det komplette eksempelet finner du her.
Skrevet av:
Robin Olsson Omslandseter og Rebekka Olsson Omslandseter