Visste du at datavarehuset Snowflake opererer med t-skjorte størrelser eller at det er arkitekturen som gjør den mest unik?
Hva er Snowflake?
Snowflake er et cloud datawarehouse som er regnet som et datawarehouse-as-a-service. Noe av det som gjør det unikt, er at datavarehuset består av tre lag:
- Storage layer
- Compute layer
- Cloud service layer
Det er uendelig med muligheter for å skalere på kryss av alle de tre lagene, siden de er uavhengige. Snowflake har også noen særegne funksjoner som vi skal ta en nærmere titt på.
Om forfatteren av innlegget
Navn: Bjarte Botnevik
Kontor: Stavanger
Hva jobber du med? Jobber som Data Engineer
Nåværende i prosjekt for: Equinor Subsurface Data Fundamentals
En "fun fact"/ interesse: Store deler av tida utenom jobb blir brukt til fysisk aktivitet, enten det er på golfbanen, på helsestudio, på sykkelsetet eller iført joggesko.

Er Snowflake konkurransedyktig?
I de fleste diskusjoner jeg har hatt rundt Snowflake, oppstår spørsmålet: “Hvordan kan Snowflake konkurrere med de største skyaktørene som Microsoft Azure og Amazon AWS?”. Dette er en misforståelse. Snowflake konkurrerer overhodet ikke mot Microsoft og Amazon sine skytjenester, men heller mot de respektive datavarehus- og/eller database-tjenestene. Snowflake kommer ikke inn istedenfor Azure og AWS, men i TILLEGG til disse plattformene.
Arkitektur
Da Snowflake sin arkitektur er det mest unike ved Snowflake, er det dette vi vil fokusere på i denne artikkelen. Snowflake er en hybrid av Shared Disk- og Shared Nothing-arkitektur. Det kan også kalles “multi cluster shared data”-arkitektur.
Shared Disk Architecture vs. Shared Nothing Architecture
Shared disk - Alle ressurser bruker samme lagringssystem/disk. Hensikten med dette var for å ha data på én sentral plass, og tilgjengeliggjøre den for flere databaser. Dette gjør at alle ressurser er 100% avhengig av dette lagringssystemet, feiler det, så feiler alle ressurser. Den kan ikke skaleres mer enn disken. Hvis man skal skalere (vertikalt), blir det dyrt.
Det er også utfordringer med “data concurrency”, som krever kompleks håndtering av lesing og skriving fra de forskjellige datanodene samtidig. Det er denne komplekse logikken som hovedsaklig skaper en flaskehals for Shared Disk-arkitekturen.
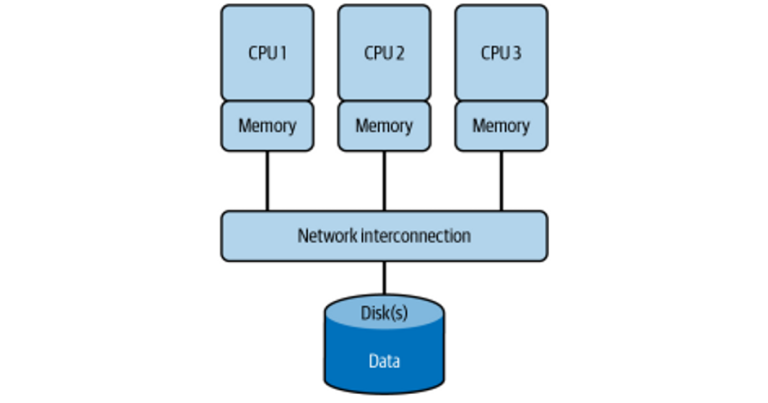
Shared nothing - Arkitekturen er delt inn i noder. Hver node har sin del av data, sammen med databehandlingsressurser. Derfor oppstår ikke samme problem med avhengighet, er det en node som feiler så skaper ikke det problem for andre noder. Den kan skaleres horisontalt, ved å legge til flere noder.
Derimot kan ikke lagringsplass og databehandlingsressurser skaleres separat. Hvis data skal bli delt mellom nodene, må CPU, minne og disk lagring bli delt på tvers av nodene. Dette fører til uønsket mengder av overhead. Det er også vanskelig å finne riktig balanse mellom lagring og databehandlingsressurser, noe som kan føre til at ressurser til tider kan være ubrukt og unødvendig.
.png)
Snowflakes arkitektur
Snowflake er en hybrid mellom Shared Disk og Shared Nothing. Lagring og kalkuleringsressurser er separert, noe som fører til at disse kan skaleres separat og er helt uavhengige. Figuren under viser hvordan de tre lagene er bygd opp.
.png)
Cloud service layer - Dette er hjernen til Snowflake, alle interaksjoner med Snowflake skjer via dette laget. Den tar seg av aktiviteter som autentisering, tilgangskontroll og kryptering. Hver gang en bruker prøver å logge inn via Snowflake sitt brukergrensesnitt (Snowsight) vil "Cloud service layer" ta seg av den forespørselen. Når brukeren skriver en SQL-spørring vil den også bli behandlet av "Cloud service layer", samt optimalisering og hurtigminne av spørringer.
Compute layer - Snowflakes kalkuleringslag blir kalt "virtual warehouse", eller det virtuelle varehuset. Disse er dynamiske inndelinger av kalkuleringsressurser, bestående av CPU, minne og hurtigminne. Et virtuelt varehus er nødvendig for å kunne gjøre de aller fleste operasjoner i Snowflake.
Snowflakes arkitektur tillater separasjon av lagring og databehandling, som betyr at ethvert virtuelt varehus kan få tilgang til de samme dataene som et annet, uten noen problem eller innvirkning på ytelsen til de andre varehusene. Dette er fordi hvert av Snowflakes virtuelle varehus opererer uavhengig og den deler ikke databehandlingsressurser med andre virtuelle varehus.
Forskjellige størrelser av virtuelle varehus kan bli satt opp før å møte behov. Snowflake opererer med tradisjonelle t-skjorte-størrelser på sine størrelser av virtuelle varehus, fra X-Small til 4X-Large. Størrelsen tilsier hvor mange servere det virtuelle varehuset har. Figuren over viser hvordan inndelingen av virtuelle varehus.








