Introduksjon til maskinlæring og naturlig språkprosessering
Maskinlæring og AI er i vinden. «Alle» er interessert, og «alle» mener at det er fremtiden. Og som teknologer er vi kanskje veldig nysgjerrig på hva dette går i og hvordan vi kan ta det i bruk. Og selv om det er utdannelser som gir god trening i AI, data science og lignende, så er det mulig at dette også kan bli et nytt verktøy i kassen for utviklere.

Denne artikkelen er beregnet på utviklere som har lyst til å prøve seg på maskinlæring. Vi skal her bruke maskinlæring for å løse et av de mest klassiske problemene innenfor naturlig språkprosessering: tekstklassifisering. Vi skal gjøre dette på norsk, da det sannsynligvis er på det språket mange kommer til å måtte implementere programmer, samt at det finnes få ferdige løsninger tilgjengelig (de fleste er dessverre på engelsk). Ingen forhåndskunnskaper er nødvendig for å forstå denne artikkelen, utover utviklererfaring med enten Java eller C#. Vi kommer til å bruke maskinlærings-rammeverket Encog, som er tilgjengelig enten fra NuGet eller Maven.
Hensikten med denne artikkelen er å hjelpe leseren med å komme i gang med maskinlæring generelt, og tekstklassifisering spesielt. Det er ikke meningen å beskrive den beste måten å løse dette problemet på, men noen forslag til andre løsninger vil bli nevnt.
Maskinlæring i korte trekk
Nesten all maskinlæring krever følgende seks steg:
- Innhente relevant data.
- Prosesser data på en «smart» måte.
- Del i to grupper: trenings- og testdata.
- Lag modell med gitte parametere.
- Bruk treningsdata til å lære opp modellen.
- Bruk testdata til å kontrollere modellen.
Dersom man i steg seks ikke er fornøyd med resultatet så må man gå tilbake til et av de foregående stegene og gjøre endringer. Dette kan innebære å hente mer data, prosessere den på en bedre måte, justere modellen, osv.
Tips:
Maskinlæring innebærer mye prøving og feiling. Resultatet blir aldri en algoritme som beviselig løser det aktuelle problemet, og maskinlæring brukes som oftest i tilfeller der en slik algoritme ikke finnes.
Men før vi begynner på noe av dette så må vi bestemme hva vi ønsker å oppnå i steg seks.
Tekstklassifisering
Problemstillingen vi skal se på her er definert som følger: plasser en tekst i en av flere kjente kategorier. Dette er ofte brukt for spam-filtre, sortering av kunde e-mail, chat-bot, osv.
Vi kan da bestemme at i steg seks måler vi suksess ut fra hvor stor prosent av testdataene, som i vårt eksempel er en samling med tekster, modellen greier å plassere i den rette kategorien.
Kunstige nevrale nettverk
For å løse det nevnte problemet skal vi bruke et kunstig nevralt nettverk. En full beskrivelse vil være for omfattende, men en liten introduksjon vil gjøre resten av prosessen lettere å forstå. Dette vil være ganske forenklet, og ikke inneholde flere detaljer enn de vi har bruk for videre.
Et kunstig nevralt nettverk består av tre eller flere nivåer: inputnivået, minst ett skjult nivå (som oftest), og outputnivået. Hvert nivå består av en eller flere noder, og alle noder har en rettet kant til alle nodene på det neste nivået.
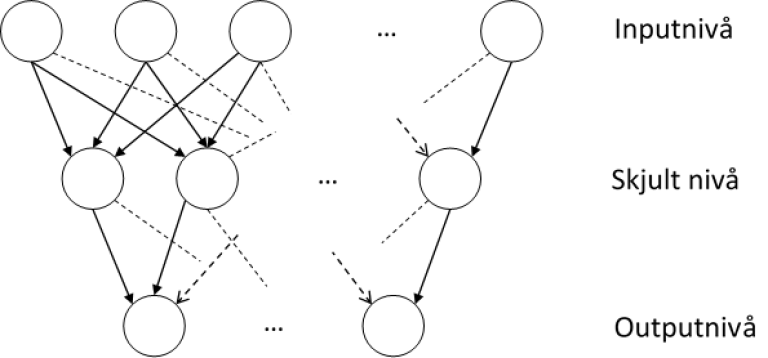
Hver node har en verdi (som typisk er mellom -1 og 1), og hver kant en vekt (som er mellom 0 og 1). Verdien til input-nodene beskriver den gjeldene instansen av problemet, og verdiene på alle de skjulte og output-nodene er beregnet av det vi kaller en aktiveringsfunksjon (vi kommer tilbake til den). Denne funksjonen tar som input verdien fra alle nodene i nivået over, vektet av kantene.
Antallet noder på hvert nivå, samt antallet skjulte nivåer, er opp til oss å bestemme. Her kan man teste forskjellige konfigurasjoner for å se hva som gir det beste resultatet.
Tekst som input
For at vi skal kunne bruke et nevralt nettverk for å løse den aktuelle problemstillingen ser vi at vi må kunne konvertere en tekst til en liste med tall, hver mellom 0 og 1.
Dette løses enkelt med en teknikk som kalles "bag-of-words". Den går ut på at vi teller forekomster av hvert ord i en tekst. Gitt denne teksten, så får vi følgende bag-of-words: "John liker hunder, og de liker ham og."
|
John |
Liker |
Hunder |
Og |
De |
Ham |
|
1 |
2 |
1 |
2 |
1 |
1 |
La oss ta et nytt eksempel: "Hun gikk til skolen, og hun skal gå hjem."
|
Hun |
Gikk |
Til |
Skolen |
Og |
Skal |
Gå |
Hjem |
|
2 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
Den observante leser vil her kanskje lure på om ikke "gå" og "gikk" er samme ordet. Det er et godt spørsmål, og for å unngå forvirringer vil vi ikke snakke om ord, men heller leksemer. Et leksem er et fellesbegrep for alle formene av et ord, eller det abstrakte konseptet. Dvs. "gå, går, gikk, gått" er det samme leksemet. For enkelhetsskyld representerer vi hvert leksem med grunnformen. Det andre eksempelet vårt blir da:
|
Hun |
Gå |
Til |
Skole |
Og |
Skal |
Hjem |
|
2 |
2 |
1 |
1 |
1 |
1 |
1 |
Å bruke leksemer i stedet for ord gir mange fordeler. Det holder størrelsen på bag-of-words nede, samt at modellen ikke vil bli forvirret av forskjellige former av det samme leksemet. For eksempel, hvis vi skal trene en modell som skal kunne skille mellom forskjellige typer kjøretøy, så er det en fordel at den forstår at «bil», «biler», «bilene» betyr det samme. Men dette må vurderes nøye i hvert brukstilfelle. Dersom vi skulle trent en modell for å sjekke om en tekst er skrevet i nåtid eller fortid så ville bruk av leksemer i stedet for ord åpenbart virke mot sin hensikt.
For å kunne konvertere ord til leksemer så anbefales Nasjonalbibliotekets sin SCARRIE database.
Det er svært viktig at leksemene som inngår i hver bag-of-words er de samme for hver trenings- og testfil. Det vil si at leksemet som hver posisjon i tabellen representerer er det samme for samtlige data, selv om antallet på denne posisjonen er null.
For eksempel, dersom vi har tre setninger:
- "Katter er dyr."
- "Hunden er morsom."
- "Hunder er hunder"
Da vil leksemlisten vår bli "katt, er, dyr, hund, morsom", og bag-of-words for hver setning blir:
|
|
|
Katt |
Er |
Dyr |
Hund |
Morsom |
|
1 |
1 |
1 |
1 |
0 |
0 |
|
|
2 |
0 |
1 |
0 |
1 |
1 |
|
|
3 |
0 |
1 |
0 |
2 |
0 |
|
Dette kan da fungere som input til det nevrale nettverket, og for akkurat denne instansen av problemet ville vi hatt fem input-noder, en for hvert leksem.
Kategori som output
Akkurat som for input, så er output fra et kunstig nevralt nettverk en liste med tall, hver mellom 0 og 1. Og det er opp til oss å bestemme hvordan denne listen skal tolkes. Her velger vi at antallet output noder er likt antall kategorier, og at for en gitt kategori i så hadde node i verdien 1, og alle andre null. Med for eksempel tre kategorier blir det da:
- Kategori1 -> (1, 0, 0)
- Kategori2 -> (0, 1, 0)
- Kategori3 -> (0, 0, 1)
Trenings- og testdata
Mange som leser dette har antageligvis en tanke om hvilken type tekst de ønsker å klassifisere. Men dersom man bare gjør dette for øvelsens skyld, så kan man velge å bruke offentlige dokumenter som trening- og testdata. Man kan laste ned flere forskjellige dokumenter, fjerne alle tall og symboler, dele dokumentene opp i enkeltfiler på for eksempel 100 ord hver, og bruke navnet på opphavsdokumentet som kategori.
Tips:
Når forfatteren gjorde denne øvelsen valgte han tre stortingsmeldinger om henholdsvis IT-sikkerhet, miljøvern og bioteknologi, samt 2016 årsrapportene fra DNB og Den Norske Kirke. Hver av disse fem dokumentene ble delt opp i filer slik som beskrevet, og resultatet ble ca. 150 filer fra hver kategori: IT, Miljø, Bio, DNB og Kirke.
Deretter deler vi filene fra hver kategori opp i trenings- og testdata. Det er en fordel å ha omtrent like mange fra hver kategori, og et godt utgangspunkt er 100 treningsfiler og 40 testfiler. Unngå å bare velge de første 100 som treningsdata, og gjør gjerne fordelingen tilfeldig.
Det er gjerne lurt å begynne med å klassifisere to kategorier, og så øke antallet etter hvert.
Prosessering av data
Neste steg er å finne listen over leksemer som blir grunnlaget for alle bag-of-words. Dette gjøres ved å gå gjennom leksemlisten i Scarrie databasen, og fjerne de som ikke forekommer i treningsfilene (dette begrenser størrelsen på bag-of-words). Det er viktig at den endelige listen beholds, da vi vil trenge den både for trening og testing.
Vi står da igjen med noen tusen leksemer. Dette høres kanskje ikke så mye ut, men det kan være nok til at treningen av det nevrale nettverket går svært sakte. Det er mange måter å håndtere dette problemet på, men vi skal bruke en ganske enkel løsning. Gitt at leksemlisten består av x elementer, så opprettet vi en ny liste av størrelse x/10. Hver forekomst av et leksem i blir registret i posisjon i%(x/10) i den nye listen (da vil alle forekomster av leksem 1, 11, 21 osv. bli ansett som det samme). Den endelige størrelsen på bag-of-words blir da en tiendedel av den opprinnelige størrelsen.
Tips:
Leserne som er interessert i andre (og bedre) metoder kan lese om «feature hashing». Det kan også være nyttig å bruke «Laplace smoothing».
Vi kan nå bruke denne leksemlisten til å lage en bag-of-words for hver treningsfil. Hvis hver fil består av hundre ord (som ikke nødvendigvis er unike), og bag-of-words har noen hundre elementer, så sier det seg selv at det er mange felt som står tomme.
Til slutt, all input til det nevrale nettverket må være mellom 0 og 1, og vi kan ganske enkelt oppnå dette ved å dele alle verdiene i hver bag-of-words med den høyeste.
Trening og testing
Som nevnt vil vi bruke Encog til å lage, trene og teste modellen vår. Fordelen med Encog er at det implementerer mange rammeverk og algoritmer for maskinlæring, og det er enkelt og raskt å komme i gang med. Vi vil her vise pseudo-kode for de delene av programmet som bruker Encog klasser og metoder.
I koden under antar vi at trenings- og testdata er tilgjengelig som to 2-dimensjonale double-array. Hver bag-of-words er n lang, og det er m kategorier. Videre har vi k sett med treningsdata, og t sett med testdata. Da blir tabellen med treningsdata n * k, og testdata blir n * t. Videre så må vi for trening av modellen også ha fasiten (targetData i kode-eksemplene). Dette er også en to-dimensjonal double-array, og har størrelse m*k.
Trening
Vi begynner ved å definere utgangspunktet for modellen:
network = new BasicNetwork();
network.AddLayer(
new BasicLayer(null, false, n));
network.AddLayer(
new BasicLayer(new ActivationSigmoid(), true, n / 2));
network.AddLayer(
new BasicLayer(new ActivationSigmoid(), false, m));
network.Structure.FinalizeStructure();
network.Reset();
Det nevrale nettverket beskrevet av koden består av et input-nivå av lengde n, et skjult nivå av lengde n/2, og et output-nivå av lengde m. Videre har vi valgt en "Sigmoid aktiveringsfunksjon" som brukes for å beregne output på hver node. En Sigmoid funksjon er veldig vanlig å bruke til dette, men prøv gjerne andre alternativer, og se hva som gir best resultat. De to siste linjene nullstiller nettverket, slik at vi er klar for å begynne treningen.
I neste steg beskriver vi hvordan treningen skal foregå:
trainingSet = new BasicMLDataSet(trainingData, targetData);
trainer = new ResilientPropagation(network, trainingSet);
Den første linjen definerer treningsdataene. Den neste oppretter selve treneren. "Resilient (back) propagation" som brukes her er en god metode for trening av nevrale nettverket. Men det finnes andre, og også her kan leseren selv prøve forskjellige alternativer.
Til slutt kan vi gjennomføre treningen:
while (trainer.Error > TargetAccuracy && epoch <= MaxEpochs) {
trainer.Iteration();
epoch++;
}
Her har vi på forhånd definert TargetAccuracy og MaxEpochs, slik at treningen avsluttes enten når vi har oppnådd en ønsket nøyaktighet, eller når den har kjørt en viss mengde ganger uten å komme i mål. Et greit start-sted for disse to konstantene er 0.00001 og 600.
Tips:
Skulle vi ha brukt korrekt metodikk så burde vi hatt ett datasett til: valideringsdata. Dette settet bruker vi i hver iterasjon av treningen for å teste modellen. Vi stanser treningen når modellens treffsikkerhet på valideringssettet begynner å synke. Dette unngår «overfitting».
Testing
Testing av modellen gjøres ganske enkelt, gitt testdata som en double-array av størrelse n.
output = new double[m];
network.Compute(testData, output);
Til slutt konverteres output tilbake til kategori, f.eks. (0, 1, 0) -> Kategori2.
Her er det verd å merke at output vil sjeldent bestå av bare null og en. I de fleste tilfeller vil samtlige verdier være et desimaltall i mellom disse to. Vi velger her å tolke det som at den største verdien ble rundet opp til en, og alle andre til null. Men man kunne valgt andre måter å forstå dette på, f.eks. at den største verdien representerer modellens førstevalg, den nest-største det neste alternativet, osv. Prøv gjerne, og se hva som fungerer for din instans av dette problemet.
Konklusjon
Vi har sett på en metode man kan komme raskt i gang med maskinlæring og naturlig språkprosessering.
Metoden som er beskrevet bør, med forbehold om hvilken data som brukes, gi en treffprosent mellom 80 og 90. Det vil si at 80 til 90% av testfilene blir forbundet med den korrekte kategorien. Dette kan uten tvil forbedres ved å f.eks. endre strukturen på det nevrale nettverket, forbedret feature hashing, eller andre teknikker. Verktøyene implementert av rammeverket Encog kan også brukes til å løse mange andre problemstillinger med maskinlæring, og det er opp til leseren å tenke seg hvilken som kan være interessante for dem og deres bedrifter.
Til sist er det verd å påpeke at modellen vi har trent er en "black box" i den forstand at den er flink til å løse det aktuelle problemet, men vi vet ikke hvorfor. Vi kan ikke "åpne opp" det kunstige nevrale nettverket og peke på akkurat den koblingen som gjør at modellen kan skille en kategori fra en annen. Nettverket består av hundrevis av noder og tusenvis av kanter, hver med sin vekt, og det er helheten som produserer resultatene vi ønsker.

